¿Qué es el web scraping? Cómo recopilar datos de sitios web
Anuncio
Los raspadores web recopilan automáticamente información y datos a los que generalmente solo se puede acceder visitando un sitio web en un navegador. Al hacer esto de forma autónoma, los scripts de raspado web abren un mundo de posibilidades en minería de datos, análisis de datos, análisis estadístico y mucho más.
Por qué es útil el raspado web
Vivimos en una época en la que la información está más disponible que en cualquier otro momento. La infraestructura en el lugar utilizada para entregar estas mismas palabras que está leyendo es un conducto para un mayor conocimiento, opinión y noticias de las que nunca ha sido accesible para las personas en la historia de las personas.
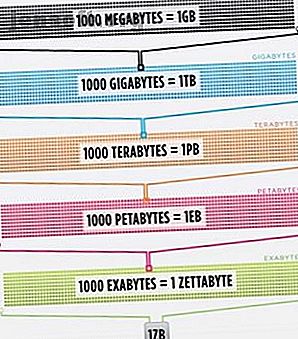
Tanto es así, de hecho, que el cerebro de la persona más inteligente, mejorado al 100% de eficiencia (alguien debería hacer una película sobre eso), aún no podría almacenar 1/1000 de los datos almacenados en Internet solo en los Estados Unidos .
Cisco estimó en 2016 que el tráfico en Internet excedió un zettabyte, que es 1, 000, 000, 000, 000, 000, 000, 000 bytes, o un sextillion bytes (adelante, ríete en sextillion). Un zettabyte es aproximadamente cuatro mil años de transmisión de Netflix. Eso sería equivalente a si usted, lector intrépido, transmitiera The Office de principio a fin sin detenerse 500, 000 veces.

Todos estos datos e información son muy intimidantes. No todo es correcto. No es relevante para la vida cotidiana, pero cada vez más dispositivos envían esta información desde servidores de todo el mundo directamente a nuestros ojos y cerebro.
Como nuestros ojos y cerebros realmente no pueden manejar toda esta información, el raspado web ha surgido como un método útil para recopilar datos mediante Internet. El raspado web es el término abstracto para definir el acto de extraer datos de sitios web para guardarlos localmente.
Piense en un tipo de datos y probablemente pueda recopilarlos raspando la web. Las listas de bienes inmuebles, los datos deportivos, las direcciones de correo electrónico de las empresas en su área e incluso las letras de sus artistas favoritos se pueden buscar y guardar escribiendo un pequeño guión.
¿Cómo obtiene un navegador datos web?
Para comprender los raspadores web, primero tendremos que entender cómo funciona la web. Para acceder a este sitio web, usted escribió "makeuseof.com" en su navegador web o hizo clic en un enlace de otra página web (díganos dónde, en serio queremos saber). De cualquier manera, los siguientes dos pasos son los mismos.
Primero, su navegador tomará la URL que ingresó o en la que hizo clic (Sugerencia: coloque el cursor sobre el enlace para ver la URL en la parte inferior de su navegador antes de hacer clic para evitar ser punk) y formará una "solicitud" para enviar a un servidor El servidor procesará la solicitud y enviará una respuesta.
La respuesta del servidor contiene HTML, JavaScript, CSS, JSON y otros datos necesarios para permitir que su navegador web forme una página web para su placer visual.
Inspección de elementos web
Los navegadores modernos nos permiten algunos detalles sobre este proceso. En Google Chrome en Windows, puede presionar Ctrl + Shift + I o hacer clic con el botón derecho y seleccionar Inspeccionar . La ventana presentará una pantalla similar a la siguiente.

Una lista de opciones con pestañas alinea la parte superior de la ventana. De interés en este momento es la pestaña Red . Esto proporcionará detalles sobre el tráfico HTTP como se muestra a continuación.

En la esquina inferior derecha vemos información sobre la solicitud HTTP. La URL es lo que esperamos, y el "método" es una solicitud HTTP "GET". El código de estado de la respuesta aparece como 200, lo que significa que el servidor vio la solicitud como válida.
Debajo del código de estado se encuentra la dirección remota, que es la dirección IP pública del servidor makeuseof.com. El cliente obtiene esta dirección a través del protocolo DNS ¿Por qué cambiar la configuración de DNS aumenta su velocidad de Internet? ¿Por qué cambiar la configuración de DNS aumenta su velocidad de Internet? Cambiar su configuración de DNS es uno de esos pequeños ajustes que pueden tener grandes ganancias en las velocidades diarias de Internet. Lee mas .
La siguiente sección enumera detalles sobre la respuesta. El encabezado de respuesta no solo contiene el código de estado, sino también el tipo de datos o contenido que contiene la respuesta. En este caso, estamos viendo "text / html" con una codificación estándar. Esto nos dice que la respuesta es literalmente el código HTML para representar el sitio web.

Otros tipos de respuestas
Además, los servidores pueden devolver objetos de datos como respuesta a una solicitud GET, en lugar de solo HTML para que la página web los represente. Interfaz de programación de aplicaciones (o API) de un sitio web ¿Qué son las API y cómo las API abiertas están cambiando Internet? ¿Qué son las API y cómo las API abiertas están cambiando Internet? ¿Alguna vez se ha preguntado cómo "hablan" los programas en su computadora y los sitios web que visita? el uno al otro? Leer más normalmente utiliza este tipo de intercambio.
Examinando la pestaña Red como se muestra arriba, puede ver si hay este tipo de intercambio. Al investigar la tabla de clasificación abierta de CrossFit, se muestra la solicitud para llenar la tabla con datos.

Al hacer clic en la respuesta, se muestran los datos JSON en lugar del código HTML para representar el sitio web. Los datos en JSON son una serie de etiquetas y valores, en una lista esbozada en capas.

Analizar manualmente el código HTML o pasar por miles de pares clave / valor de JSON es muy parecido a leer Matrix. A primera vista, parece galimatías. Puede haber demasiada información para decodificarlo manualmente.
¡Raspadores web al rescate!
Ahora, antes de ir a pedir la píldora azul para salir de aquí, ¡debes saber que no tenemos que decodificar manualmente el código HTML! La ignorancia no es felicidad, y este bistec es delicioso.
Un raspador web puede realizar estas tareas difíciles para usted La API Scrapestack facilita el raspado de sitios web para obtener datos La API Scrapestack facilita el raspado de sitios web para datos ¿Busca un raspador web potente y asequible? La API de scrapestack es de inicio gratuito y ofrece muchas herramientas útiles. Lee mas . Los marcos de raspado están disponibles en Python, JavaScript, Node y otros idiomas. Una de las formas más fáciles de comenzar a raspar es usando Python y Beautiful Soup.
Raspar un sitio web con Python
Comenzar solo requiere unas pocas líneas de código, siempre que tenga Python y BeautifulSoup instalados. Aquí hay un pequeño script para obtener la fuente de un sitio web y dejar que BeautifulSoup lo evalúe.
from bs4 import BeautifulSoup import requests url = "http://www.athleticvolume.com/programming/" content = requests.get(url) soup = BeautifulSoup(content.text) print(soup) Muy simple, estamos haciendo una solicitud GET a una URL y luego colocando la respuesta en un objeto. La impresión del objeto muestra el código fuente HTML de la URL. El proceso es como si fuéramos manualmente al sitio web y hiciéramos clic en Ver código fuente .
Específicamente, este es un sitio web que publica entrenamientos de estilo CrossFit todos los días, pero solo uno por día. Podemos construir nuestro raspador para obtener el entrenamiento todos los días y luego agregarlo a una lista agregada de entrenamientos. Esencialmente, podemos crear una base de datos histórica basada en texto de entrenamientos que podemos buscar fácilmente.
La magia de BeaufiulSoup es la capacidad de buscar a través de todo el código HTML utilizando la función incorporada findAll (). En este caso específico, el sitio web utiliza varias etiquetas "sqs-block-content". Por lo tanto, el script necesita recorrer todas esas etiquetas y encontrar la que nos interesa.
Además, hay una serie de
Etiquetas en la sección. El script puede agregar todo el texto de cada una de estas etiquetas a una variable local. Para hacer esto, agregue un bucle simple al script:
for div_class in soup.findAll('div', {'class': 'sqs-block-content'}): recordThis = False for p in div_class.findAll('p'): if 'PROGRAM' in p.text.upper(): recordThis = True if recordThis: program += p.text program += '\n' Voilà! Nace un raspador web.
Escalando el raspado
Existen dos caminos para avanzar.
Una forma de explorar el raspado web es usar herramientas ya construidas. Web Scraper (¡gran nombre!) Tiene 200, 000 usuarios y es fácil de usar. Además, Parse Hub permite a los usuarios exportar datos raspados a Excel y Hojas de cálculo de Google.
Además, Web Scraper proporciona un complemento de Chrome que ayuda a visualizar cómo se construye un sitio web. Lo mejor de todo, a juzgar por su nombre, es OctoParse, un poderoso raspador con una interfaz intuitiva.
Finalmente, ahora que conoce los antecedentes del raspado web, cree su propio pequeño raspador web para poder rastrear y ejecutar Cómo construir un rastreador web básico para extraer información de un sitio web Cómo construir un rastreador web básico para extraer información de un Sitio web ¿Alguna vez ha querido capturar información de un sitio web? Puede escribir un rastreador para navegar por el sitio web y extraer justo lo que necesita. Leer más por sí solo es un esfuerzo divertido.
Explore más sobre: Python, Web Scraping.

